논문 링크:
Bayesian Inverse Contextual Reasoning for Heterogeneous Semantics- Native Communication
This work deals with a heterogeneous semantics-native communication (SNC) problem. When agents do not share the same communication context, the effectiveness of contextual reasoning (CR) is compromised calling for agents to infer other agents’ context be
ieeexplore.ieee.org
출처: H. Seo, Y. Kang, M. Bennis and W. Choi, "Bayesian Inverse Contextual Reasoning for Heterogeneous Semantics- Native Communication," in IEEE Transactions on Communications, vol. 72, no. 2, pp. 830-844, Feb. 2024.
요약
이전 연구에서 다루었던 SNC(Semantics-Native Communication)는 맥락 추론 CR(Contextual Reasoning)을 활용해 에이전트들 사이의 통신 효율성과 효과성을 증가시켰다. 그러나 에이전트마다 맥락이 다른 Heterogeneous SNC 상황에선 이런 맥락 추론이 잘 동작하지 않아 그 성능이 떨어질 수 있다. 이렇게 공유하는 맥락이 없는 시나리오를 가정하기 위해 아래 그림에서 3번째 에이전트 Carol이 추가된다. 캐롤은 앨리스와 밥 사이의 통신 맥락과 과제에 대해서 모르고 있는 상황이며 CR을 기반으로 앨리스와 밥 사이의 맥락을 추론하는 것이 목표다. 캐롤은 Inverse CR을 통해 앨리스와 밥 사이의 맥락에 대해 추론하고 이를 바탕으로 다시 앨리스와 밥 사이에서 CR을 기반으로 소통한다.

이 논문에선 이렇게 맥락을 역추론하는 방법으로 Bayesian iCR을 제안한다. 이 방법에선 Bayesian 추론과 Markov Chain Monte Carlo sampling(MCMC)를 사용하여 앨리스와 밥 사이의 맥락 X를 추정한다. 이 과정을 거친 추론 방법은 높은 맥락 추론 정확도를 보이나 연산량이 많다. 이를 해결하기 위해 LCR(linearized CR) 방법이 제안되는데 이는 두 층짜리 선형 신경망을 이용해 빠른 계산을 가능케 한다. 이를 통해 추론 정확도, 통신 효과성, 역추론이 가능한 가역성을 얻을 수 있다. 이 LCR은 inverse 과정에도 적용되어 inverse LCR (iLCR)로 사용될 수 있으며 이는 Bayesian iCR 보다 적은 계산량으로 더 높은 맥락 추론 성능을 보여준다.
위 그림에서 캐롤은 앨리스와 밥사이의 통신 결과를 바탕으로 실제 맥락 행렬 X, 행동과 개념의 사전확률 p(A), p(C)를 복원해 내는 것이 목표다. 이를 수행하기 위해 이 논문에선 Bayesian iCR 방법이 제안되는데 이는 Bayesian 추론과 MCMC 샘플링을 이용해 맥락과 확률을 복원해 낸다. 이 방법은 사후 확률(posterior distribution)이 계산 가능한 형태인지의 여부에 상관없이 샘플링을 통한 근사가 가능하다. 또한 이 방법은 맥락 행렬 X에는 sparsity를 반영한 분포, 사전 확률에는 벡터 구조를 적용해 두 단계로 샘플링을 진행한다. 데이터 유형에 맞는 처리가 가능하기에 고차원 문제를 작은 문제로 분할해 해결할 수 있다.
그러나 이런 Bayesian iCR 방법은 CR을 계속 반복해야하기에 계산 비용이 높다는 단점이 있다. 이에 대한 해결책으로 CR을 선형화 해 복잡한 반복 계산 과정을 줄여 효율성을 높이는 Linearizing Contextual Reasoning(LCR) 방법을 제안한다. Φ는 T를 입력, R(T)를 출력으로 하여 학습시키며 이를 통해 R(T)에 대한 근사를 아래 식의 좌변과 같이 얻을 수 있다. 기존의 CR 모델과 달리 이렇게 선형화된 모델은 invertibility와 연산비용 측면에선 강하나 CR보단 보안성이 약하다.
$$
\text{vec}(\tilde{\mathcal{R}}(\mathbf{T})) = \Phi \, \text{vec}(\mathbf{T})
$$
이렇게 선형화시킨 LCR 모델을 iCR 과정에도 적용해 iLCR모델을 아래와 같이 나타낼 수 있다. 이는 Restricted Isometry Property (RIP) 조건을 만족하기 위해 추가적인 제한을 걸어 학습된다. 또, 이 논문에서 사용하는 tMH 방법은 OMP와 달리 매 반복마다 벡터 항목을 갱신한다. 이에 따라 계산량은 더 크지만 오류에 강해 안정적으로 문맥을 복원할 수 있다.
\[
\mathbf{vec}(\,\bar{\mathbf{R}}\,) = \mathbf{vec}\big(\,\tilde{R}(\mathbf{T}) + \mathbf{N}\,\big) \tag{25}
\]
\[
= \boldsymbol{\Phi}\,\mathbf{vec}(\mathbf{T}) + \mathbf{vec}(\mathbf{N}) \tag{26}
\]
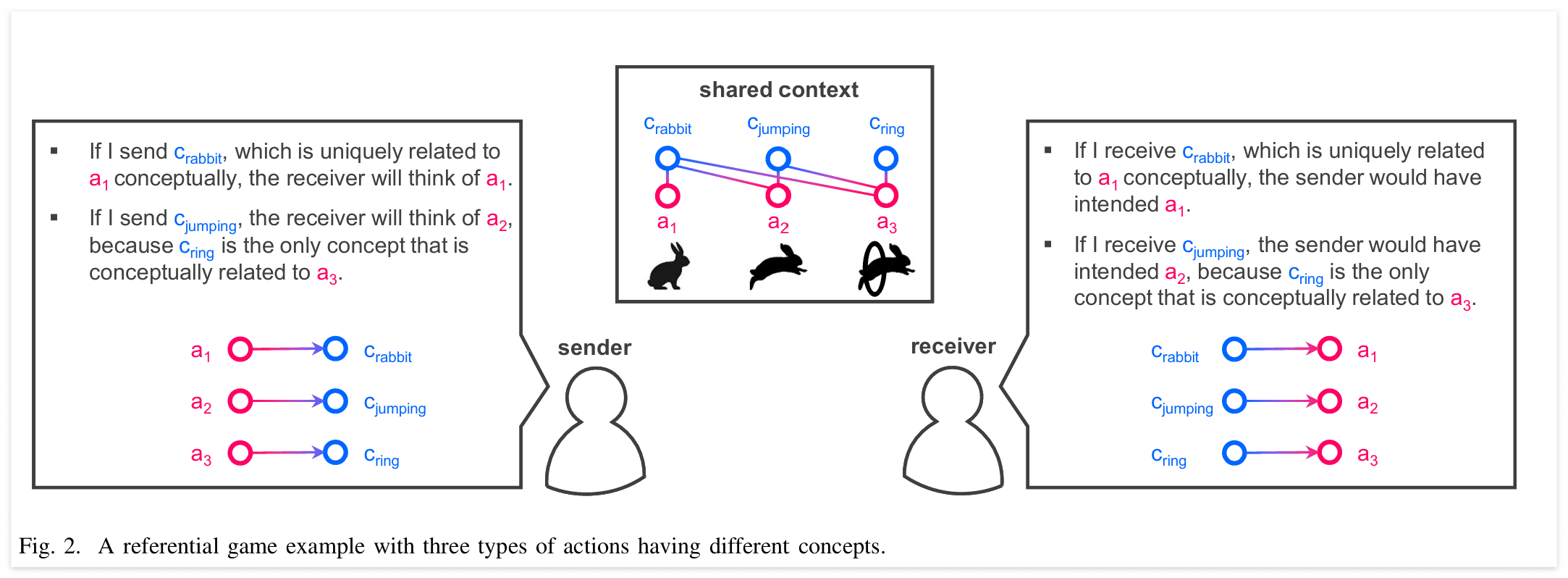
아래는 Referential Game에 대한 두가지 예시를 보여준다. 이는 맥락을 반영한 rational 한 화자/청자 사이의 대화임을 가정한다. 화자는 c_rabbit을 전송하기 전 맥락을 공유하는 청자의 행동에 대해 추론한다. 화자는 청자가 c_rabbit이 a1의 유일한 개념이기에 청자가 이를 바탕으로 a1을 떠올릴 거라고 생각한다. 마찬가지로 청자는 c_rabbit을 받는 경우 이것이 a1의 유일한 개념이기에 화자가 a1을 의도했을 것이라고 추론한다. c_jumping을 전송하는 경우 c_ring은 a3와만 연결된 개념이기에 수신단에서 a3를 배제한 a2를 선택할 것이라고 추론한다. 그리고 수신자는 이와 동일한 과정을 거쳐 c_jumping을 수신하는 경우 a3를 의도한 것임을 알게 된다. 만약 공유된 맥락이 없는 경우라면 수신자는 c_jumping을 받았을 때 c_rabbit을 받지 않는 이상 이것이 토끼가 점프하는 동작인 a2를 의도한 것임을 알지 못한다. 즉 이렇게 맥락이 공유된 상황에선 c_jumping을 전송하는 것만으로 a2를 추론할 수 있기에 통신 효율성이 향상된다.
아래 그림은 Bayesian iCR을 사용했을 때 세가지 실험 결과를 나타낸다. 그림 (a)는 목표했던 확률 분포와 iCR을 사용해 경험적으로 얻은 확률 분포를 비교한다. (b)는 개념의 수가 증가할수록 X, y, z가 목표했던 개념과 멀어지는 것을 보여준다. 마지막으로 그림 (c)는 3가지 방법을 T에 대한 복원 오류로 비교한다. 분포가 사전에 알려진 경우 모르는 경우보다 더 적은 복원에러를 보였다. 여기서 MAP는 사전 확률을 알고 있음을 가정하여 나온 결과이기에 iteration 수에 따라 일정하다, 그러나 사전 확률은 알려져 있지 않기에 MAP 방법은 실용적이지 못하다고 할 수 있다.

이어서 아래의 (d), (e), (f)는 Bayesian iLCR에 대한 결과를 나타낸다. (d)와 (e)를 (a), (b)랑 비교했을 때 목표하는 분포에 더욱 근접한 것을 확인할 수 있다. 또 재복원 에러에 대해서도 선형화를 도입한 결과 더 적은 오류를 나타냈다.

아래의 (a), (b)는 선형화 기법이 연산량을 크게 줄일 수 있다는 것을 보여준다.

아래 두 그림은 CR의 선형화 정도가 sparsity에 따라 달라지는 것을 보여준다. (a)에선 0이 아닌 샘플이 희귀할수록, 즉 s가 작을수록 loss가 빠르게 감소하며 학습이 빨라지는 것을 확인할 수 있다. 그림 (b)에서는 선형화를 CR 모델에 적용하는 것이 더 나은 invertibility를 가지는 것을 보여준다. 또한, RIP 조건을 적용한 L2 손실함수를 사용하는 경우 더 높은 invertibility를 가지게 된다.

다음으로, 아래 그림은 적용한 모델에 따른 SNC 통신 효과를 비교한다. 앨리스와 캐롤 사이의 iCR과 iLCR을 비교했을 때 선형화 기법을 적용한 것이 더 좋은 성능을 보인다. 다음으론 노란색 그래프쌍과 파란색 그래프 쌍에 주목해 볼 수 있다. 노란색 그래프는 선형화를 적용하지 않은 CR과 iCR에 대한 비교로 선형화를 적용한 방법보다 그 차이가 큰 것을 확인할 수 있다. 이는 앞서 다루었듯, 선형화 기법이 Invertibility를 증가시켜 역맥락 추론을 원활하게 하기 때문이다.

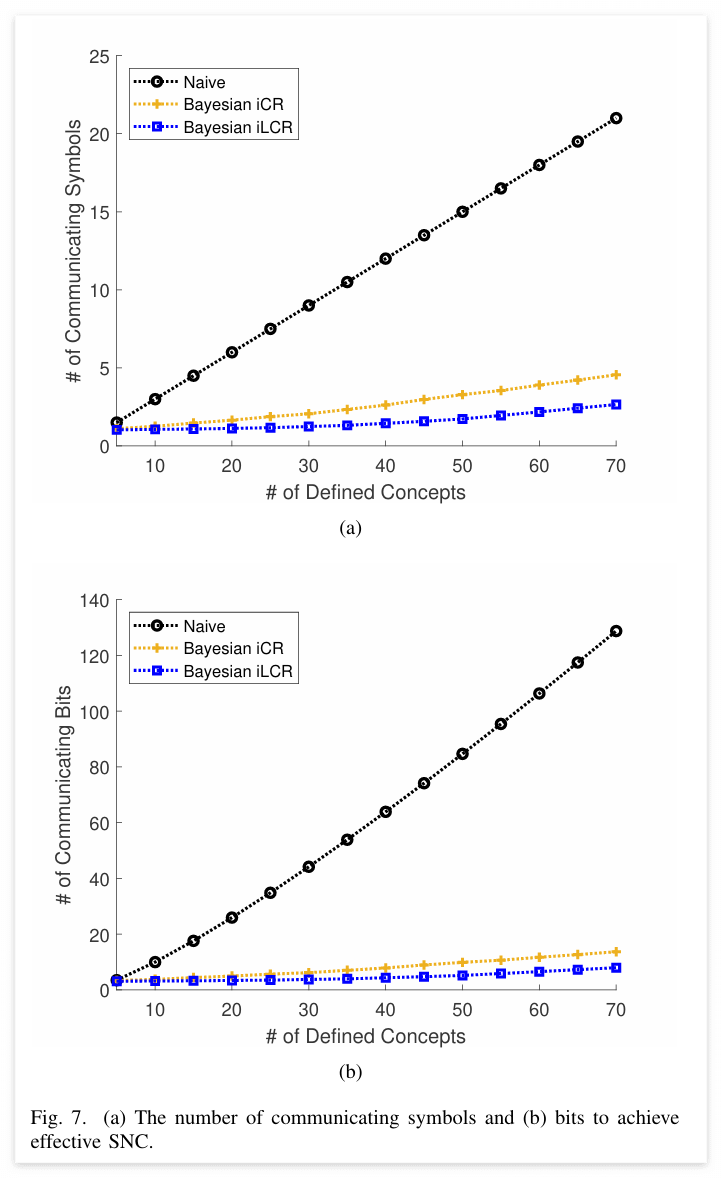
마지막으로 아래 figure는 0.9보다 큰 SNC effectiveness를 달성하기 위해 필요한 심볼 수를 나타낸다. 선형화를 적용한 방법은 더 적은 심볼 및 비트수로도 통신 성능을 유지한다. 이는 통신 자원이 제한된 환경에서 제안한 방법이 효과적일 수 있다는 것을 나타낸다.
한계 및 발전 방향
- 높은 계산 복잡도: 논문에서도 언급했듯, Bayesian iCR은 tMH를 반복 사용하므로 계산 비용이 매우 커 실시간 적용이나 자원 제약 환경에서 제약이 발생할 수 있다.
- LCR은 사전학습 필요성: iLCR은 LCR 모델의 사전 학습을 전제로 하기에 사전 학습이 어려운 경우 적용이 어려워질 수 있으며 다른 방법과의 완전한 공정 비교가 불가능하다.
- 행렬 Φ의 RIP 보장: LCR을 통해 얻는 측정행렬 Φ가 RIP 조건을 만족하도록 보장하는 것은 NP-hard 문제이기에 학습 과정에서 완전한 RIP 보장을 확보하긴 어렵다.
- 문맥 희소성: 선형화 가능성과 압축 센싱 기반 복원이 잘 작동하려면 문맥 X가 충분히 희소해야하나 실제 환경에서는 이와 같은 희소성이 나타나지 않아 성능 저하가 발생할 수 있다.
- 사전 분포 정보: tMH의 성능은 prior 정보 (know prior) 유무에 따라 달라지며 실제로 prior가 불명확할 때 정확도 면에서 차이가 있을 수 있다.
- 계산 비용, 사전학습 의존, RIP 보장 문제, 희소성 가정 등 현실 적용을 위한 한계를 해결하기 위한 실환경 검증 연구로 이어질 수 있다.